Kerfuffle Over EU Copyright Study
Two weeks ago Pirate MEP Julia Reda unearthed a study, commissioned by the Internal Market DG of the EU in 2013, on the impact of piracy on the market for sales of media, otherwise referred to as the ‘displacement rate’. She became curious about because she came across the original tender documents online but was unable to find it published anywhere. Her attempts to access the document via a freedom of information request were unsuccessful, but after she acquired and published the document, the Commission released the report itself. The timing itself looks like a smoking gun.
My guess is that not many people will actually read this 300 page document, another salvo in a long-running struggle by the different sides in the copyright debate to rally the authority of economic analysis and statistics to their side. This one has drawn attention because of a suspicion that the Commission decided to suppress the research findings because they poorly fit their pro-copyright orientation and the push for a new, more stringent, copyright directive in particular. The Internal Market DG has long had a proclivity for back-room activity in support of the Copyright industry, and spawned the European Observatory on Infringements of Intellectual Property Rights in 2012.
Apparently – I haven’t read it myself – the report supports the argument that while music and games do not suffer negative effects due to piracy, blockbuster movies do endure losses. But this is a familiar Punch & Judy show. I don’t think we should lend credence to the idea that the policy outcomes are actually being settled by a careful weighing of the evidence in a rational debate – that’s obscuring how lobbying and exercise of power shapes EU regulation.
If we’re going to spend a little time genuflecting at the altar of positivism, I’d be more interested in reading about the new face of cultural production: self-sustaining youtubers; self-publishing of books; the fall and rise of the music business; changes in film economics and the background of filmmakers etc. Fourteen years ago the music industry launched its mass lawsuits against p2p users, but for much of the new field of cultural production the conditions of reproducibility are an environmental fact, and its enabling technologies are the preconditions for their own viability – cheaper models of production and distribution. This is a cultural production that adapts to the digital rather than fear it as an existential threat. (That sounds old!) That said, the optimistic predictions of net utopians have been exposed as naive; the gate-keepers are still here, but they are now in a different point in the production cycle (marketing, platforms etc).
Such research is surely being done, I’d be curious to know if the Commission is doing any of it and paying any heed to what emerges.

Autumn, Giuseppe Arcimboldo, 1573
Reddit Abandons Do Not Track – But Never Really Embraced It
Reddit today announced that they are changing their privacy policy and ‘phasing out Do Not Track’. This is sad, but their approach to DNT was so toothless that it isn’t much of a material blow, but it is a loss on the level of public discourse. It is instructive, however, to see the owners of the purported grassroots internet line up behind the rhetoric and misrepresentations used by the ad industry to disparage Do Not Track.
Let me be clear though, it is absolutely the case that enabling DNT in your browser does not currently provide almost any protection from online tracking. If you want protection use a tracker blocker. That’s because DNT is simply a message, transmitted in the headers of your web requests, it is a signal that the user does not want to be tracked but leaves it to the recipient server to decide whether to honour that request or not. DNT is not a self-enforcing mechanism, neither a shield nor a sword. The publishing and advertising industry has largely decided that it is in its interests to ignore it. But by refusing to voluntarily respect DNT, they leave users with no option but to defend themselves through the installation of tracker blockers or the use of browser with built-in tracking protection such as Brave, Opera and Firefox (in the case of the latter two this must be enabled by the user). Of course once they do that and block all the ads (which track users) they are attacked by the industry’s representatives as thieves, ingrates who have refused to keep their side of an imagined bargain (‘we give you content, you look at our ads’).
Back to Reddit. Let’s parse their statement today:
“We’re making some changes to our Privacy Policy. Specifically, we’re phasing out Do Not Track, which isn’t supported by all browsers,
False. On the desktop, DNT is supported by all major browsers, Chrome, Firefox, Microsoft Edge, Safari.
doesn’t work on mobile,
False. On mobile DNT is supported by Safari on iOS, Chrome and Firefox on Android. Apps pose another challenge but that’s a different matter.
and is implemented by few—if any—advertisers,
Advertisers will only support DNT when there is the Adtech there to enable it – this in turn requires demand from publishers. Once the demand exists there is an incentive for the emergence of a structure to support ads functioning on a basis other than surveillance, for example through the refinement of methods for contextual placement. Did Reddit ever attempt to seed the market for such ads? Not that I know. Even though one of their adtech suppliers was capable of providing them with DNT compliant service.
and replacing it with our own privacy controls. DNT is a nice idea, but without buy-in from the entire ecosystem, its impact is limited. In place of DNT, we’re adding in new, more granular privacy controls that give you control over how Reddit uses any data we collect about you. This applies to data we collect both on and off Reddit (some of which ad blockers don’t catch). The information we collect allows us to serve you both more relevant content and ads. While there is a tension between privacy and personalization, we will continue to be upfront with you about what we collect and give you mechanisms to opt out. Changes go into effect in 30 days.”
Blah blah blah. This is industry boilerplate.
The ‘privacy controls’ and discredited ‘Ad choices’ program are really methods to keep users inside the tracking corral, exhausting their precious privacy budget. People generally have a limited amount of time/attention to invest in protecting themselves online; if doing so is overly complex, involved, or of doubtful efficacy, users will be deterred from taking action.
These schemes are an alibi for the everyday data dragnet conducted by these companies, not as a real opt-out. People do not have the time to manage each individual site nor can they penetrate opaque corporate data practices. Users want to fire and forget, and DNT’s greatest virtue is that it is a simple one-time setting that sends the same message to every web-site every time – it comes in under the privacy budget.
This has been a short ride; Reddit announced their limited support for DNT in a low key manner in November 2015. Weirdly, an examination of their privacy policy revisions shows that they actually dumped DNT in November 2016. During that year the only actual difference in treatment for DNT users was that third party trackers were not loaded on the pages they viewed. What the formal abandonment of the policy means, presumably, is that information about subreddit use will henceforth be available to advertisers in some form, and third party trackers will be used to connect your use of reddit with visits to other sites within those trackers reach.
They Call it ‘Web of Trust’ – Orwell Fumed
Panorama 3 is a current affairs and investigative television show broadcast by NDR, a regional public TV station and part of national broadcaster ARD. In autumn 2016 the program investigated the trade in German internet users’ browser data (in German). Posing as a ‘data driven consultancy firm’ (!) they approached companies looking for such data, and they were not disappointed. As a taster for what they could expect if they coughed up 10,000 euros per month, they received a free database containing the browsing data of three million Germans over one month.
Using a basic script they were able to identify many of the individuals behind the clicks – names could be extracted from logins to email accounts, social networks, ecommerce sites etc. From the web history they could see that there was a judge who was shopping for robes in the morning and S&M paraphernalia by night, a police officer using Google translate to craft an international request on a live investigation, medical queries, financial data of various degrees. Where did the data come from? The journalists worked with a security analyst and identified the source as the browser add-on Web of Trust. this ironically titled software offers its users assessments of website legitimacy as they surf, and is supposed to help protect users from being scammed. Once installed in a browser WOT was siphoning off users browsing activity and shipping it off to the data market, without the knowledge of their users of course.
The broadcast caused quite a stir in Germany and spread into the international sphere. Three days after the initial German broadcast, Firefox withdrew WOT from its add-on store and blocked further versions. And the company itself pulled it from Chrome. Later that month the Finnish Data Protection Authority (WOT is/was a Finnish company) announced that the case had been referred to the police. Ownership of the company is unclear. There was no public statement made by WOT for six weeks after which they announced that there had been a ‘major review’ of their software. No explanation was offered for what had been disclosed. At the end of December the journalist behind the program gave an extended presentation of her research (in German) at the Chaos Computer Club conference.
Despite this the WOT extension has been allowed back into the Firefox and Chrome stores in recent months. There are a large number of five star ratings which are ecstatic about the software and make no mention of the gigantic scandal, surely evidence of the ease with which ratings systems are being gamed. One wonders what Mozilla and Google’s position on these cases is – is it enough that WOT revise their privacy policy, offer an obscure ‘opt out’ and they’re good to go? WOT claim to have revised their anonymization techniques for the data (!), but who has audited this, where are there samples available to independent researchers?
Of course the list of companies exploiting user data without their consent is very long indeed. And more companies want in on it all the time! Many of them do not sell this data on the open market but keep it to themselves in order to control the nexus with the user for advertising placement, others, however, are really in the data trading game. I wonder if at some point the advertiser-data block will knife the data-traders so as to depict themselves as the good guys, it might be a smart move but would risk bringing the whole sector into question.
+Kaos (of autodidacts and adepts of Primo Moroni)
Autistici/Inventati, together with Rise Up!, is the preeminent provider of network resources and infrastructure to social movements worldwide. An English translation of the Italian tech collective’s history has now been published. The account should get some oxygen at hacker events over the next while and fills an important gap in the literature around politics and technology. The origin and development of the sharply political sensibility behind the collective is set out here in a rich combination of recent Italian history and participant self-narration.
“Condividere saperi, senza fondare poteri”
‘Share knowledge, without installing power’
– Primo Moroni (1)
Mediterranean hacktivism is distinct from the ‘hacker spaces’ of the US and the engineering influenced hacker culture of northern Europe (think Chaos Computer Club), more confrontational and embedded in a broader political atmosphere. This is a world where computer science faculties have competition from autodidacts who stay up late in squatted industrial buildings, equipped with recycled hardware running free software, a net connection, and subversive intent. Their knowledge is different, as is the way they produce it: outside of institutions and political parties, somewhat and unevenly self-organised, and yes, chaotic.
Published by Agenzia X in Italian in 2012, +Kaos covers the decade after the collective’s birth, in the ferment of the summer of 2001, before the trauma of Genoa and the political upending of September 11th. But it also looks back to the genesis of radical computer networking in the 1980s & 1990s – a homage to the pioneers and their predecessors.. From April 2001 onwards this is a tale of the slow assembly of a global infrastructure, punctuated by periodic setbacks, occasionally technical but mostly legal, and more joyfully the sleepless annual ritual of the hackmeeting. Like the networks A/I supports these legal attacks were both global and local, and functioned as a catalyst for the development of innovative solutions and resilient attitudes. The English edition comes with a technical glossary and extensive footnotes to help non-Italians get a grip of the peninsula’s peculiarities.
The world it describes already appears somewhat distant, before the Arab Spring and Occupy Wall Street, the Syrian Civil War and Trump. But history seemed to accelerate in 2001 as well – how to stand up to these phases is the question and the challenge. This is an account of one attempt to do so, a collective agency combining operation of technical systems with political analysis amidst conflict, crisis and opportunity.
(1) This phrase has served as the unofficial motto of A/I since its creation. Primo Moroni (1936-1998) was a key figure of the revolutionary and countercultural milieu in Milan for over forty years. An autodidact, writer, and professional dancer, he opened a bookshop, Calusca/City Lights, in 1971 which became a faucet for political and cultural heterodoxy, including the introduction of beat and hippie literature that would quickly have a significant impact in Italy. His book L’orda d’oro, co-authored with Nanni Ballestrini, remains the definitive account of the revolutionary movement in Italy in the ’60s and ’70s.
Respectful Ads not Acceptable Ads
When you’ve becomes too familiar with the an industry’s trade organizations, it is a sure sign that you have entered the vale of tears. Forget the newly minted worries about fake news, this is the world of paid opinions, a hall of mirrors where facts are irrelevant; broadcast power combined with political clout are what matters.
In March the advertising industry published its conclusions regarding acceptable ‘ad experiences’. They found, unsurprisingly, that users hate autoplay video ads, pop-ups, countdown ‘prestitials’ and a series of other things. The new acronym behind this standard, the Coalition for Better Ads (CBA), includes Facebook, Google and entities such as the Interactive Advertising Bureau (IAB) and Network Advertising Initiative (NAI). The CBA’s strategic purpose is to find ways to stanch the demand for adblockers upstream, cutting off the legs from uncontrolled third parties like Adblockplus, whose ‘Acceptable Ads‘ criteria have been enforced by ABP since 2012.
But this competing standard can’t undermine the adblockers unless it is given form as software. Thus the rumor that Google are going to integrate an adblocking feature with Chrome; it won’t be an adblocker as we know it, but one which implements the CBA’s rules. (If you want a browser with integrated adblocking or tracker blocking, Opera and Brave offer that functionality already.)
The CBA and the Acceptable Ads program have something in common: neither address user concerns unconnected with format, but to do with the tracking and surveillance architecture which sits at the core of the advertising industry. In their eyes it is just a case of users being irritated by annoying formats, but it’s not, and research about the motivations behind adblocker adoption have repeatedly demonstrated that, including research commissioned by the IAB itself. The following chart comes from a report (1) produced by the IAB last summer:
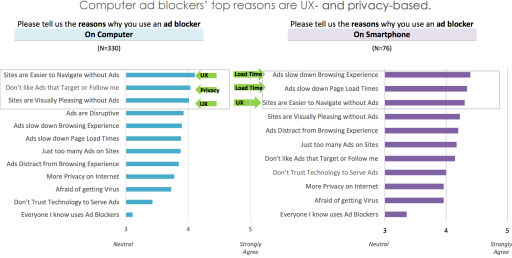
fig 1. Ad Blocking: Who Blocks Ads, Why and How to Win Them Back, IAB & C3 Research, 2013
The discussion needs to be emancipated from the straitjacket of ‘format acceptability’ and turned towards the relationship between publishers and readers. Treating readers/users respectfully means to value their time and attention, acknowledge and abide by their privacy preferences, and to find ways to deliver utility in ways they want.
Such an attitude does not come naturally to the many members of the CBA who spent the last half year lobbying against the FCC’s privacy rules, enabling ISPs to spy on their customers. These organizations prefer fig-leaf self-regulatory schemes that claim to offer privacy choices, programs dismissed by the former FTC commissioner Julie Brill. Now the Network Advertising Initiative have the hubris to organize a ‘Privacy Hackathon’ – anyone considering participating might wonder if it’s sensible to align their privacy work with an organization which fought for the repeal of consumer privacy rules at the FCC.
(1) See chart on page 20, Ad Blocking: Who Blocks Ads, Why and How to Win Them Back, IAB, June 2016.
The FCC and the Tectonics of Commercial Surveillance
It’s been a dreadful week if you care about privacy online in the US. Last October the FCC passed broadband consumer privacy rules that constrained ISPs from commercialising users’ browsing data. These rules required that users opt-in to such usage rather than having to opt-out. Companies intent on profiting user data hate opt-in requirements as they know that many will not agree to these uses. Conversely many people who value privacy do not opt-out because they are unaware the option exists, don’t know how to avail of it, or the choice may be presented to them in terms which are confusing – in such cases uses tend to stick to the default setting.
Ajit Pai, the new head of the FCC, made clear his opposition to both the privacy and net neutrality rules when he was one of two Republican minority appointees on the last Commission. Reversal of the privacy rules was lobbied for intensely by the Cable providers (NCTA), wireless companies (CTIA) and the Telecom sector (US Telecom). They were supported by almost the entire advertising sector, notably the Interactive Advertising Bureau (IAB). The sole exception is the Digital Advertising Alliance who have been conspicuous by their silence. DAA represents online advertising behemoths such as Google and Facebook and their interests are somewhat at odds with those of the infrastructure owners.
Sensitive or Insensitive?
Until last October browsing records were in the main classified as insensitive information. Sensitive information is characterized as that relating to financial and health data and information relating to children. This is the Federal Trade Commission’s classification, and is what allows Adtech to collect information about users without their consent. In 2015, as part of the net neutrality process, Broadband provision was re-categorized from information to telecommunications service. This may sound trivial but it meant ISPs became classed as ‘common carriers’ and placed under the jurisdiction of the FCC. The FCC then determined that browsing history as a whole is sensitive data, requiring companies to get opt-in to be allowed to use it.
Competition between Privacy Invaders
The cable, wireless and telecom companies hate this because they want to get into the personal data fueled advertising business, and their position sitting over the pipe of user data gives them an unparalleled to observe. Google and Facebook meanwhile track users over as much of the web as they can, on their own widely popular properties, and using third party cookies and social media buttons (like!, G+) to track users on other sites who are connect to their infrastructure for advertising or marketing purposes. Effectively this means that they can surveil most users over the lion’s share of their online activity (see the research from Engelhardt & Naranyan). These two colossi currently dominate internet advertising and are obviously keen to suppress the emergence of new competitors. But they also want to protect against the risk of their own data collection being redefined as involving sensitive information – the problem could spread from the FCC to their overseers (ha!) at the FTC. that’s why Google opposed this redefinition and lobbied against it.
Secondly, the DAA have their own self-regulatory privacy framework. This describes the interface of three classes of actors with user privacy: first parties (sites that you visit intentionally); third parties (domains that you interact with unknowingly because they provide services to the first); service providers, who are ISPs. In their schema service providers must get user consent for the use of data for reasons other than performance tuning. This explains why the DAA actively opposed the new privacy rules in the run-up to their introduction but is quiet now. It also explains the slurs being thrown at privacy advocates that they are acting as stooges for Google.
Policy Gobbledygook
With this background let’s parse the Orwellian gobbledygook issued by industry lobbyists after their victory:
“We appreciate today’s Senate action to repeal unwarranted FCC rules that deny consumers consistent privacy protection online and violate competitive neutrality (#1). … Our industry remains committed to offering services that protect the privacy and security of the personal information of our customers (#2). We support this step towards reversing the FCC’s misguided approach and look forward to restoring a consistent approach to online privacy protection that consumers want and deserve (#3).”
#1 = These rules put us at a competitive disadvantage to Google/Facebook, they can intrude, we can’t – it wasn’t fair!
#2 = We’ll decide what information of your is personal and what is not (it’s all entertainment data, right?!). You can trust us.
#3 = Now that users have no privacy protections from either the biggest publishers or the infrastructure providers, the playing field field is finally level! Yes, we could have lobbied to have Google and Facebook subjected to the same constraints and evened things up that way, but nah, silly idea.
The big winners are companies like Verizon who bought AOL to move their business towards online advertising and is in the process of taking over what’s left of Yahoo. They’ve bought themselves an advertising infrastructure with lots of data of their own and can now exploit the data trail of their own customers. AT&T are also in celebratory mood and have been gushing about the Trump administration more generally. Back in 2013 they operated a program called ‘internet preferences’ which instituted additional charges for users who opted out of having their usage data exploited to expose them to behavioural advertising. Have achieved their goal of overturning the regulations, Telecoms are claiming they won’t sell users’ browser history. But selling data is not the model of Google or Facebook either – once sold the competitive advantage the data provides is lost. Instead they control access to its exploitation on long-term exploitation: they administer the data, marketers pay them directly or indirectly to take advantage of it.
Self-Defense?
As the gatekeeper to the network the ISP can see and read the URLs of all the pages you visit. If the site connection is via HTTPs then only the domain you are visiting is exposed – a minor mitigation but another good reason to use HTTPs Everywhere.
There are two technical responses to this situation both of which are unsatisfactory.
Tor: if you use Tor to access the web then your traffic is encrypted and routed via a series of other servers before being reaching the destination website. Thus the traffic is concealed from the ISP but at the cost of performance – all that circumnavigation to get your request to its final destination slows down the process. If it sounds too technical for you, think again: the Tor browser requires zero configuration overhead.
VPN: if you use a virtual private network then all your web traffic is routed securely through another server, so the ISP can only observe you connecting to that resource. That’s great but VPNs are paid services, typically between $30 and $100 a year. If you use a VPN for this purpose you hope that they are more trustworthy than the ISP, but the VPN world is fragmented among small providers and has no consistent audit standard.
End2End: Privacy Theatre or Promise Deferred?
Back in October I recalled how the Google had announced in June 2014 that it was going to develop and ship a plugin for Chrome, E2EMail, which would give Gmail users the chance to use end to end encryption. This effort was announced in the aftermath of the Snowden disclosures when surveillance was a major public issue and many Google engineers were still smarting from the discovery that a NSA project called ‘Muscular‘ was slurping Google data as it traveled between their systems – and joking about it.
Google announced a number of security changes in response to the revelations almost all focused on the internal processes at the company, E2EMail however was something that users themselves would be able to choose to use. With an estimated billion users Gmail is the biggest provider of free email and well integrated encryption functionality could offer users real privacy and security gains. Of course there are plenty of alternatives, from running GPG/PGP locally on your email client to clients like Mailpile which have encryption built in, but Google has brand power as well as unquestioned engineering talent and with that comes a certain ability to influence user behaviour.
But two and a half years later there is still no plugin. Last week a post on the blog of google’s security team announced that E2EMail was ‘leaving the nest’ and would now be opened up to a community of developers around the project’s Github page. Observers are wondering if this is Google’s way of walking away from any responsibility for it. Wired published an article worth reading which also details some of the challenges involved in the development of such a tool. Google’s deployment of encryption on other users tools such as their messaging apps has been half-hearted – so far they have only implemented the Signal protocol on Allo and it is not enabled by default. This is in contrast to WhatsApp for example, which ships with encryption on by default; most users are loathe to reconfigure their software which is why default settings are so critical.
A 2016 Almanac
February
Following the San Bernardino massacre of December 2015, the FBI seek to force Apple to assist in unlocking the data on the culprit’s phone, sparking a debate pitching national security against privacy.
March
Major news sites hit by malvertising payload which delivers ransomware to users computers. Security, as well as privacy concerns, data consumption and weariness at excessive and intrusive advertising drive the further growth of adblocking.
+++
On March 28th the Department of Justice dropped its case against Apple after the FBI announced that they had found a means to unlock the phone and access the data on it
April
The EU formally adopts General Data Protection Regulation, which will come into effect in May 2018.
+++
Dave Carroll documented the absurd gymnastics required from parents by Facebook should they want to opt their kids out of ads.
+++
WhatsApp announces the integration of encryption functionality for calls and text, implementing the protocol developed by Open Whisper Systems. For the first time a true mass market user tool deploys encryption as default.
May
Elsevier, academic publishing behemoth, buys SSRN, a key repository for free scholarly articles online. They start to remove access to some articles. Luckily there is Sci-Hub.
June
Startup Score Assured offers service to profile potential tenants for landlords. Prospective renters will have to provide them with details of all their social media accounts.
+++
23/6 Britain votes to leave the EU. Bad news for the EU and for Ireland especially, but possibly good news for privacy and data protection advocates. Axel Arnbrak explains.
+++
28/6 Google changes its privacy policy so that the combination of the Double Click advertising cookie (which tracks users all over the double click network i.e. a large part of the web) with Personally Identifying Information (PII) is no longer an opt-in matter.
+++
In a Brussels Appeal Court Facebook successfully overturned a decision forbidding them from tracking non-users for advertising purposes around the web. It was found that the Belgian courts did not have jurisdiction. Such complaints are to be dealt with in Ireland.
July
The EU Commission issues its implementing decision for the Privacy Shield agreement on the transfer of data from the EU to the US, a jury-rigged replacement for the Safe Harbour provisions challenged by Max Schrems and found invalid by the European Court of Justice in October 2015.
+++
14/7 Microsoft vs US: the US Department of Justice’s attempted extraterritorial application of the Stored Communications Act to access a user’s email on a server located in Ireland. The Second Circuit appeals Ct. held in favor of Microsoft.
+++
Google withdraws appeal to the UK Supreme Ct. in Vidal Hall – legal action and damages possible for breaches of Data Protection law even where there is no monetary loss. The decision is widely viewed as enabling a more muscular enforcement of data protection rules.
August
WhatsApp start sharing users’ telephone numbers with Facebook who want to use them for their magic advertising sausage recipe. Elsewhere Facebook meanwhile was recommending the users connect with each other on the basis because they shared the same psychiatrist. Nothing to hide, indeed.
+++
Draft proposals for copyright revisions in the EU are leaked. Stomachs heave.
September
Further evidence of the value of ‘relevant’ ‘targeted’ advertising is provided by this account by a woman who had a miscarriage but continued to be pitched pregnancy and birth related products.
+++
Digital Rights Ireland announces its legal challenge to Privacy Shield.
October
Open Whisper Systems, the entity behind he development of encrypted communications app Signal, announced that they had been subpoenaed for information for information on one of their users. The only information held by them was the date and time of the user’s registration and the time of their last connection to the Signal service’s servers. No content, no contact lists, nada.
+++
Unlike Yahoo, who were caught trawling the entirety of their email user population at the behest of the US government, losing their head of security in the process, which seems careless.
+++
In other mass surveillance news the UK’s Investigatory Powers Tribunal (oversight body for MI5, MI6 & GCHQ) finds that the collection of bulk communications data and retention of bulk personal data sets were in breach of the European Convention Human Rights.
+++
A month now seems incomplete without a Facebook outrage and they were called out by ProPublica for targeting or enabling exclusion of users based on race.
November
Before the US election there is coverage of the Trump’s data based campaign to reduce Clinton supporter turnout by targeting them with ads focused on demoralising them.
+++
9/11: Trump elected: hard to believe that the apparatus revealed by Snowden will soon be in his hands. This is a transcript from a TV broadcast with Trump from 2005:
An audience member asked Mr. Trump for his opinion of Watergate’s hero, Deep Throat (Mark Felt, Vice- Director of the FBI).
DT: “I think he’s disgusting. I think he’s scum. I don’t care how old he is, how sick he is, I think he ought to be arrested. He was an FBI agent, essentially, and he was ratting on the President. He could have done something against the President, he could have reported the President, he could have resigned and said something.”
23:52 MJ: “What do you think would have happened to him if he had actually gone to his superior and told him about this?”
23:52 DT: “Well he only had one superior, I mean he was the second guy in the FBI. He could have resigned and had a news conference, he could have said I won’t do this but instead he was underneath, I think he’s disgusting and frankly I’d arrest him, I’d throw him in jail. I think he’s a disgusting person, totally disloyal to the country. Here’s a guy that works at the FBI, and he’s ratting out his President, and you know, hey if the President did something wrong, who knows if he did something wrong? This guy shouldn’t have done it the way he did it.”
Mark Felt’s superior at the FBI was one J. Edgar Hoover. Perhaps not the type of person to whom one would bring an ethical concern.
+++
In the desperate search for an explanation for Trump’s victory many a commentator grasp wildly at ‘fake news’ as an explanation, dumping Facebook into the muck yet again. In the UK the Admiral insurance company announces that it will price insurance premiums based on an analysis of users Facebook posts – they are quickly banned by the company.
+++
Back to advertising and privacy: a German TV journalist pretends to be a digital marketing agency and gets a free test drive of web browsing data on 3 million Germans from a broker who had sourced the data through a browser plugin – Web of Trust – marketed as a user protection tool. Data acquired implicated identifiable members of the judiciary in kinky sex and confidential information about a criminal investigation. Politicians scratch their heads and wonder how such a thing could happen. — -?
+++
17/11 the world’s greatest BitTorrent site dedicated to music, what.cd, shut down after a raid affecting part of their server infrastructure in France. Having existed for nearly a decade and built an outstanding archive its loss was widely mourned by both musicians and fans.
December
The ECJ announced its decision in the joined case of Tele2/Watson a further examination of national data retention laws after the EU directive had been struck down by the DRI’s action in 2014. The Court stated that data retention must be limited to serious criminal cases, targeted and limited o what is strictly necessary. There must also be proper oversight and other safeguards. Those placed under surveillance have the right to be notified once the investigation has concluded and the risk of jeopardising it is over.
+++
After a major consultation earlier in the year a draft of the EU’s new ePrivacy regulation is leaked.
The Machinic Sewer
The Sewer
I recently visited the Wikipedia page of a left wing German politician. She had been hit with a pie by a critic of her views on migration. Wikipedia linked to a report on Russia Today containing a video of the incident uploaded to Youtube by RT’s European unit, Ruptly. At the Youtube URL most of the videos displayed in the related content sidebar were about migration, few were from Ruptly, and many were strongly anti-immigrant. I clicked on one where an old woman was interviewed about her fears, feelings and hostility towards immigrants and closed the video after a couple of minutes. The next time that I opened Youtube seven of the ten videos recommended to me concerned immigration. Five of them were clearly produced by right wing media activists and this flavour of curation extended to the videos on the right hand column as I browsed.
This experience captures what Eli Pariser characterised as a ‘filter bubble’ in a book of the same name: I was suddenly thrust into of a media universe imagined for me on the basis of one or two clicked links, and it felt weird. Encountering world-views contrary to my own doesn’t bother me – in fact I enjoy the conflict, but the skimpy basis for subjecting me to this flood of ideological personalisation is bothersome. If the viewer is uninterested in politics and has no knowledge of the mechanism selecting the stories presented to them, what are they to make of such goings on? In this universe old ladies, innocent blond haired teenagers, and middle-aged men are at one in insisting that migrants are criminals who should be deported – is that the normcore position? Sure viewers aren’t going to swallow propaganda whole, they’ll cross reference it with their own experience and knowledge, and apply some critical thinking. But the persistence of these recommendations for about week did make me feel like as if I was surrounded. I had fallen into the filter sewer and was being sprayed with a fire-hose of horseshit.
Getting Personal
Google would argue that if I logged in to Youtube they would know more about me so I would not have ended up in the sewer. But I don’t want my media consumption tracked or personalised. Never logging in to Google is the best I can do to minimise the tracking, short of systematically using a VPN or Tor, and because I want to have some idea of what the general experience of the web is, I will not do that. I do use anti-tracking tools such as Privacy Badger, Disconnect and uBlock Origin, but none of them can fully protect you from ‘the Google’.
Of course our media environments have always had their ‘bias’, and that was the case before the internet. Journalists wax about objectivity and balance but there have always been ideological assumptions and frameworks: the basic credibility of government statements and explanations of its actions; the virtues of capitalism and liberal democracy etc – the world inside the Overton window. Because Pariser wrote the book in the internet era, and focused on the results of algorithmic filtering, it was understood (perhaps unfairly?) as arguing that the problem was new, when it was actually an evolved iteration of an older phenomenon. [It reminds me of the fear that adblocking will wreck journalism – yet newspapers were in crisis already in the 1990s as the industry became more concentrated and the new owners expanded advertising sales whilst sacking journalists, a phenomenon chronicled by Ben Bagdikian in his classic, the New Media Monopoly.]
Old media was also driven by advertising logic: demographic targeting etc but the difference lies as much in the ease of of individualised distribution as in the availability of algorithmic engines. In the newspaper age you could tell a lot about a person politically and socially from the newspaper they read, their choice was also a filter, and the advertisers who bought slots chose silos for their campaigns. But the paper still had to appeal to a mass market so the silo was big, somewhat diversified and had to cover a range of subjects. Not so today.
Futures Past
Pariser’s book is actually about personalization but he must have thought filter bubble was a catchier term. Individualized customization of information flows is heralded as the compass to navigate a sea of excess information, but this has mostly meant that users should surrender control to machinic decision making whose logic is opaque. If the past once allowed room for the illusion that this could work out well, the future is now over and we’ve seen it’s not so rosy. Information filters are needed but only as tools under the control of the user. But such user sovereignty is not a tendency the economic forces of the web want to foster. In the web of 2016 the user is object of a system designed to shape them rather than a subject to be supported in their own self-development.
In The Daily You, Joseph Turrow outlined how the the idea of the powerful consumer is promoted whilst advertisers and marketers engage in ever more intrusive information gathering processes which lead to the separation of consumers into targets and ‘waste’. And if the consumer is so potent, surely they don’t need to be protected by regulation? In the adtech world that the real end goal of personalization is revealed: collect every last bit of data so as to eventually facilitate the encounter between consumer desire and business operation. This intrusion is presented as a means of giving you ‘what you want’ and clothed in the innocuous language of ’relevance’. But the user is never asked what they want, nor given the means to control the data and advertising flows around them – the answers are to be found by spying on them.
All Our Yesterdays…
In its early days the web was embraced by media critics as a formal remedy to the ills of the mass media – newspapers, television, radio, and film. The net/web was to undermine the tyranny of intermediaries and enable a direct dialogue between individuals and groups. It was not to be. The human decision-makers have had their wings clipped, but have merely been replaced by tech-moguls (unwilling to acknowledge their editorial power) and opaque machinic processes cast as agents of divine right.
If algorithms are the new monarchs, a renewed republicanism needs to dethrone them and their owners. Users do need tools to master the data flow, but they must be under their control, transparent in their logic and designed to nurture their autonomy.
A Yahoo User’s Journey through the Unknown
“We fight any requests that we deem unclear, improper, overbroad, or unlawful,”
Ron Bell, Yahoo General Counsel
Oh Yahoo, what have you gone and done now. You strange company, whose services I have rarely had occasion to use, save for the occasional casual email account useful for keeping commercial spam away from my real address and the odd photo uploaded to flickr. And yet I cannot help but feel disappointed, because behind that Yahoo octopus whose ink barely obscures a huge advertising-surveillance system, I actually thought that there were individuals serious about defending their users’ privacy at least vis a vis the state. This belief was not without foundation: in September 2014 documents were released chronicling Yahoo’s fight at the FISA court against the NSA’s mass surveillance program. They were alone in this legal resistance. Google, who like to see and portray themselves as the user’s friend, never challenged the government in court.
I had this on my mind in the autumn of 2014, when I was getting increasingly fed up with Google search and looking for an alternative. This was driven by disgust at their relentless data harvesting and disregard for user privacy, but also by the sense that Google’s results seemed to be getting noisier, including a lot of trash and click-bait pages designed solely to exploit the modalities of the algorithm. I thus embarked on an exploration of the alternatives first Bing, then Yahoo…
This was, I know, an eccentric decision – Yahoo has if anything a worse policy regarding retention of search queries than Google. The results themselves were ok, and the key discovery that I made as I test drove the other engines is that 80% of our queries can be resolved by any of them. It is only when you are searching for an exact phrase or rarefied subject matter that the distinctions emerge. Basically Google spiders more of the web, has a better index, and has a better chance of unearthing the obscure. But I did enjoy the apostasy of using Yahoo, and bragging about it; I remember a dinner with a google engineer in SF who stared at me in amazement when I told him of my search engine heresy and explained my motivation (on that point, why are so many at Google in denial about the fact that it is an advertising company rather than a vocation to make the world better through engineering?).
Truth be told, however, this dalliance didn’t last long. After three months I had shifted again to DuckDuckGo, where I have stayed. There are wrinkles to this too: DDG buy search results from Yahoo, Bing and Yandex, which they then combine with other sources and reprocess. But DDG are sound on privacy: they never track users and they’ve adopted the EFF’s Do Not Track policy, a document close to my heart. I resort to Google only as needed, in pursuit of the esoteric and arcane, but what I thereby disclose offers such a marginal (and bizarre) view into my head and habits and I can live with that. Firefox has all the major engines in their search box, thus switching involves no overhead, and I run Opera in parallel.
So it was just a fling with Yahoo but enough to make me sick when I read that they had adapted a child pornography and malware filter and repurposed it to search the entirety of the mail passing through the @yahoo.*** system. (Incidentally the journalist who broke the story, Joseph Menn, is the author of the excellent All the Rave, which tells the story of Shawn Fanning and Napster – most enjoyable). It made me think how maddening, how insanely inconsistent, Yahoo is. Corporate Beelzebubery comes as no surprise, it’s the wild shenanigans that get to me. That’s what I intended to write about, before the rant above took shape, so here are some examples which come to mind.
Search Query Retention Times
Back in 2007 the Article 29 Working Group, an entity which drafts opinions on data protection/privacy in the EU intended to guide the actions of the Data Protection Authorities, started to breath down the necks of the search companies about how long they were retaining user query data. At the time Yahoo held the data for 13 months, Microsoft 18 months, and Google started ‘making it less identifiable’ after 9. In December 2008, Yahoo announced that they were going to start de-identifying the data after 3 months. Bravo!
Then in April 2011, Yahoo announced that they were needed to retain the data whole for… eighteen months! Otherwise they couldn’t compete! By this point Google were saying that they wouldn’t go below eighteen months either, only Microsoft’s Bing had adopted 6 months.
Do Not Track
In March 2012 Yahoo announced that they would be implementing support for the Do Not Track signal that users can enable in their browsers to tell sites that they don’t want to be tracked. This is not a message which advertising companies are pleased to receive and they have wasted a lot of people’s time at the W3C and elsewhere trying to make the subject more complex than necessary, basically as a means of stalling and sabotaging. No details were ever provided about what this Yahoo implementation would consist of, the sceptical might wonder if it was anything but air?
In April 2014 Yahoo announced that they would no longer honor DNT signals, because they believed that the default web should be ‘personalized’ i.e. tailored for you based on knowledge of what you’ve been up to; personalized thus joins relevant and interest-based as synonyms (and alarm bells) for surveillance-based advertising and content selection.
But Yahoo wasn’t finished: following a deal where they bought themselves the default search box on Firefox, they announced in November 2015 that they would be honoring DNT requests for Firefox users. Mmmmh. Why only Firefox users – oh did Mozilla make them sign up to that? Perhaps because Mozilla was one of the birthplaces of DNT? And what would honor mean exactly? It hardly matters as Yahoo may well change their position again once their takeover is complete. Or perhaps they’ll claim that they couldn’t do anything for the last five years because they were waiting for agreement at the W3C. Yawn.
Encrypted Mail
So now to the most delicious irony of all. After the uproar surrounding the Snowden revelations one of big tech’s responses was to implement encryption at various points in the network. The aspect of this closest to users was Google’s project to develop an end-to-end encryption plug-in for gmail. This was an open-source project and Yahoo declared that they would make it available for their webmail system as well. This was good for users but it would also involve a cost for the companies as both sell advertising based on scanning users’ email to select ‘relevant’ ‘personalized’ ads. If the mails are encrypted this type of analysis is not possible, resulting in lower revenues. But the NSA revelations hurt a lot of people’s pride and made the tech industry as a whole look compromised, poodles of the US government’s PRISM program, so some notional loss could be stomached.
Alex Stamos, then head of security at Yahoo, set about recruiting programmers and engineers to move it on. In March 2015 this system was ready to demo and was unveiled at SXSW. Right around then Yahoo had been requested to search their whole email traffic for a specified identifier. This was implemented secretly and without consultation with Stamos and the security team, so that when they uncovered it they mistook it for a hostile insert placed by an intruder. The rest is well known: Stamos left Yahoo shortly afterwards to become head of security at Facebook. The Chrome extension for end-to-end encryption of Yahoo mail in Chrome was never officially completed and launched, although one of the lead developers says it’s basically good to go. (Incidentally, what happened to Google’s much trumpeted efforts in this regard?)
Yahoo has many other sins uncatalogued here, but what astonishes me is how erratic and capricious they are. What would you trust them with? Better, as the Intercept suggests, to just delete your account.
Filmpiraten Crush Austrofascists (at first instance…)
An Austrian court issued an interesting judgment this week. A leftist film collective, Filmpiraten, took a court case against the far-right Freedom Party of Austia (FPÖ) for copyright-infringing reuse of material published on youtube under a creative commons license. The video at issue documented antifascist protests against the Viennese Akademikerball, an annual event held by the FPÖ which has been the target of demonstrators for many years.
Filmpiraten publish their work on the website and on youtube under a BY-NC-SA license. this means that others are free to use the material without permission providing the use is non-commercial, the work is attributed to them, and that whatever work is created downstream using it is distributed under the same licensing conditions.
The FPÖ operate their own youtube channel which includes a program called FPÖ-TV, published as work in which copyright is claimed. The court case thus concerned a violation of Creative Commons licensing terms under which the Filmpiraten had made their work available. Where a would-be user of material available under a CC license does not accept the licensing conditions, they must make a licensing agreement with the copyright holder in the usual way. Unless they are using it on the basis of one of the statutory exceptions (criticism, commentary etc).
In any case the Filmpiraten were successful in the Viennese court, so this is a significant decision for anyone interest in the treatment of CC licenses in the courts. The FPÖ will appeal. The newspaper report from Der Standard is available here (German).
Pirate Residuum
Hard to believe that only four or five years ago the Pirate Party (PP) were enjoying a German honeymoon, winning large numbers of votes and entering four regional parliaments. In the Berlin election in 2011 their results were so strong that they did not have enough candidates to fill all the seats won; candidates who ran with with little hope of getting into district assemblies were instead elected to the major-league Senate – the citywide parliament. But this unexpected triumph was to be their zenith, thereafter the party formed a circular firing squad.
During the five years of the Berlin Senate the PP parliamentary group had five chairs and co-chairs, of these four are no longer members of the party (although all continue to sit as part of the Pirate group) – Alexander Spies is the last of this band carrying a party card. Two of these former chairs were among 35 former Berlin Pirates who published an open letter in January announcing their defection to Die Linke (the Left party) while another flirts with joining the SPD. Three other PP members elected to the Senate have also departed. This means that having started the Parliamentary session with 15 representatives, they now have 8.
A further twist to the current Berlin election is that former national chairperson of the Pirates, Bernd Schlömer, is running as a leading candidate for the FDP (Liberals) having joined them last October. This is less surprising that it may seem as both FDP and Die Linke (as well as the Greens and the Pirates) once participated in the Freiheit Statt Angst! (Freedom Not Fear!) demonstrations, an annual field day of the forces opposed to mass surveillance/social control which used to take place in Berlin each September.

Pirate Party poster campaign against CDU law and order minister Frank Henkel
Berlin Election 2016
Polling currently puts the PP on 3%, well below the 5% threshold required to be allocated any seats in the Parliament. As in 2011 they are running an eye-catching campaign focused on issues where they have campaigned effectively: housing, the investigation into the billion euro airport scandal, against racism. But the nature of their public meltdown both at national and local level after 2012 has wrecked their credibility. (If one wants to vote for a neo-Dadaist anti-party Berlin already has one, die Partei, who also have a European MEP!)
The departure of former members for other parties also undermines their position as self-appointed interpreters of the magic powers of technology. This should not be underestimated: until 2012 they were effectively identified as the ‘party of the internet’, the people who wanted to usher in a streamlined tomorrow, the epitome of progress and forward thinking. But this stranglehold on the tech-dream is over.

Posters satirising the language of danger zones ‘gefahrengebiet’ and highlighting local scandals around rising rents, the endless saga of the new Berlin airport etc…
The Berlin PP was regarded as representing the party’s left-wing and some of its votes will now return to Die Linke or move to the Greens. Meanwhile, populist discontent has shifted decisively right after the controversy over refugee policy met the gunpowder of the sexual assaults in Cologne on New Year’s Eve. electorally this means pay dirt for the Alternative fur Deutschland (AFD), a toxic brew of xenophobes, alienated conservatives, economic liberals and populists, who will almost certainly enter the city Parliament this month.
Readings from the Book of (library) Genesis
In recent days it has been announced that the EU wants all scientific research papers funded through its programs to be released under Open Access by 2020*. Newspaper coverage has credited the combined efforts of the Dutch government and EU Commissioner for Research, Innovation and Science, Carlos Moedas, for the initiative. Moedas caught my attention in April due to a speech he gave on ‘open science’ which began with a reference to Alexandra Elbakyan and the controversy around Sci-Hub. He went on:
“Elbakyan’s case raises many questions. To me the most important one is: is this a sign that academic journals will face the same fate as the music and media industries? If so – and there are strong parallels to be drawn − then scientific publishing is about to be transformed.
So, either we open up to a new publishing culture, with new business models, and lead the market… Or we keep things as they are, and let the opportunity pass us by. As I see it, European success now lies in sharing as soon as possible, because the days of “publish or die” are disappearing. The days of open science have arrived.”
Until recently it would have been impossible to imagine an institutional figure use Sci-hub as a springboard for a positive vision rather than an occasion for vitriol.
Blowback
While legal action by Elsevier against Sci-Hub and Elbakyan grinds on in the US, it has succeeded only in generating large amounts of positive publicity for both – Elsevier’s attack on a library that once existed in the shadows has ended up biting the behemoth in the ass. Despite a court decision in their favor, the website remains online and usable.
Seeking to disable free access to scientific articles otherwise available only through overpriced subscriptions was never going to be a winning PR strategy. That Elsevier made an operating profit of 34% in 2014 doesn’t help their case, nor does the fact that the authors are not paid. Commentators have instead treated the liberation of academic work from copyright restrictions as an enlightenment gesture in favor of universal access to knowledge (which it is). There is sympathetic coverage all over, from Science to Le Monde ** – it’s all a far cry from the quiet annihilation of Library.nu/Gigapedia in 2012.
Academic work is special…
Such an outpouring was never going to emerge from the cases against Napster or the Pirate Bay – the shared objects at the centre of those trials were seen merely as trifling entertainment commodities. This is odd given how important shared cultural works are for shaping our identities, but somehow they are tainted by their association with pleasure and fun. Academic papers, on the other hand, are no terrain of indulgence; they are the stuff of seriousness, discipline, painful memories of homework…
Risk and Reward
With all this attention, use of Sci-Hub and Library Genesis is booming and presumably growing its holdings. Given that the entire collections are available for download via torrent it will be interesting to see if services on top of the corpus – text mining etc. Until now such techniques have been the preserve of the database owners or companies like Google, with the resources for both mass scanning efforts and sustained legal defense involved in their Library/Book project. So let’s see the unauthorised repositories become the substrate for experiment, analysis, and additional layers of meaning.
Elbakyan is now carrying a lot of personal risk and is owed our support. Aside from the injunction against her there are claims under the Computer Fraud & Abuse Act (the same law used to prosecute and intimidate Aaron Swartz). She is cagey about her location and is concerned about the threat of extradition to the US. But this must be weighed against what she has achieved: assembling and stewarding a system of self-provision for all those with inadequate access to literature wherever they are. Right now it is important that all those who believe in LibGen/SciHub state that support openly. Later this may also meant to step up and support her also materially
——
*There are caveats however, enabling exceptions for reasons of security… and intellectual property rights – an exception which could utterly undermine the rule depending on how it is interpreted.
**See also: Justin Peters’ article critiquing Science’s defence of their business model; a piece from Aaron Swartz’s former colleagues at The Baffler; the very useful bibliography regarding Sci-Hub/LibGen maintained by Stephen Mclaughlin.
Cyberspace – the Fifth domain of Warfare?
Spotted this today in Treptow, it reads:
“Germany’s freedom is also defended in cyberspace. Do what really counts.”
As you may have guessed, it is part of an advertising campaign launched by the German army to recruit people with IT training.

Demystifying AdTech
Critical discussions about tracking, targeted advertising, surveillance capitalism seem to easily stray onto the terrain of paranoia and speculation. Cookies are associated with an inchoate but rather mild evil and almost no-one can explain how they produce their odious effects.
Cookies, however, are only the first hurdle in understanding the much more opaque universe of AdTech. This is a poorly understood world in part because it is rather new and has yet to assume a stable shape. The industry is dominated by companies which are far from being household names, and they describe themselves in terms of roles which are not easily grasped – demand side platforms, data management platforms, ad exchanges etc. The jargon accompanying the recreation of the advertising pipeline for real-time delivery is just the surface manifestation of a complex technical system. Little wonder then that most people in the advertising industry itself don’t get it, never mind us mortals (aka ‘targets’ and ‘waste’) who are being bought and sold billions of times a day.
The trade press is a great source of information, as are company blogs, and even the mainstream media occasionally does something decent, but mostly it’s fragmented. Of course there’s a copious academic literature, mostly coming out of computer science, if you want to get into the detail. But for an overview one could do a lot worse that a to look at a report produced by the Norwegian Data Protection Authority last December, titled “The Great Data Race” (mercifully in English). The first half of the report (particularly pages 10-29) provide a good breakdown of the new division of labour, examine how data is collected and breakdown the actual process of ‘programmatic buying’ and real-time bidding.
For more of the context as well as a rich documentation of the consequences of the new orthodoxy, I’d recommend the work of Joseph Turow, and his book the Daily You.
-
Recent
- Kerfuffle Over EU Copyright Study
- Reddit Abandons Do Not Track – But Never Really Embraced It
- They Call it ‘Web of Trust’ – Orwell Fumed
- +Kaos (of autodidacts and adepts of Primo Moroni)
- Respectful Ads not Acceptable Ads
- The FCC and the Tectonics of Commercial Surveillance
- End2End: Privacy Theatre or Promise Deferred?
- A 2016 Almanac
- The Machinic Sewer
- A Yahoo User’s Journey through the Unknown
- Filmpiraten Crush Austrofascists (at first instance…)
- Pirate Residuum
-
Links
-
Archives
- September 2017 (1)
- July 2017 (1)
- June 2017 (1)
- May 2017 (1)
- April 2017 (1)
- March 2017 (1)
- February 2017 (1)
- December 2016 (1)
- November 2016 (1)
- October 2016 (1)
- September 2016 (1)
- August 2016 (1)
-
Categories
- /
- ACTA
- advertising
- Austria
- berlin
- books
- china
- cinema
- civil liberties
- communication
- Data Protection
- databrokers
- Dublin
- ECPO
- enforcement
- EOIIPR
- European Court of Justice
- european directives
- european regulations
- european union
- events
- France
- Germany
- hackers
- HADOPI
- history
- immateriality
- ipred
- ireland
- italy
- language
- law
- licenses
- material culture
- music
- oil21
- open video
- patent
- pharmaceuticals
- photography
- Piracy
- Pirate Bay
- Pirate Party
- satire
- social cooperation
- steal this film
- Sweden
- technology
- trade
- trademark
- UK
- wine
- WTO
-
RSS
Entries RSS
Comments RSS
